

To better understand
How and why access to data of platforms matters for us all, not just for researchers

Ok, the Mozilla Festival is probably the coolest tech event I’ve ever been to.
I went there with Artifacts last week (proudly wearing a press badge!) and spent the days bouncing between great conversations, sharp sessions on building better tech, and the general buzz of a community that still believes technology can be good.

I came home with so many notes that I knew I needed a moment to let things cool, sift through everything, and figure out what it all meant.
This edition of Artifacts is that attempt.

If I had to summarise the Festival in one word, it would be: data.
Not a shock, maybe, but it kept surfacing in almost every conversation. Fair access to data, transparency around it, and actual ownership of it came up again and again as the real foundations of a healthier internet, especially in an AI era powered by the very data we barely control.
That’s also the thinking behind Mozilla’s new Data Collective, a platform for responsible data exchange for AI training.
As E.M. Lewis-Jong, the Director, said when announcing it: “Data is power and that power should belong to the people and organizations who are creating that data”.
The same idea appeared in one of the most entertaining sessions, “The Wikipedia Test”, a game-lab by the Wikimedia Foundation that asks participants to invent policies to compensate Wikipedia for all the scraping it endures from AI companies.
(go checkout the Wikipedia test, it’s a fun one!)
The point is simple. How data is shared and used isn’t a side issue. It’s critical if we want a digital world that isn’t just extractive.
Finally, probably my favourite conversation was the “Unlearning Data Barriers: A New Framework for Access to High-Influence Public Platform Data”, led by Knight Georgetown Foundation and joined by Brandi Geurkink (interview below!), Carlos Hernández-Echevarria (Maldita.es), and LK Seiling (DSA Data Access Collaboratory).
We talked about how to secure better access to platform data, what the landscape looks like now, and why researchers and citizens still lack visibility into the places where our digital lives unfold.
We started from the Framework developed by the Knight Georgetown Foundation, that is focused on:
what data is critical to get (in yellow)
and also how to develop efficient and immediate access points (in green)
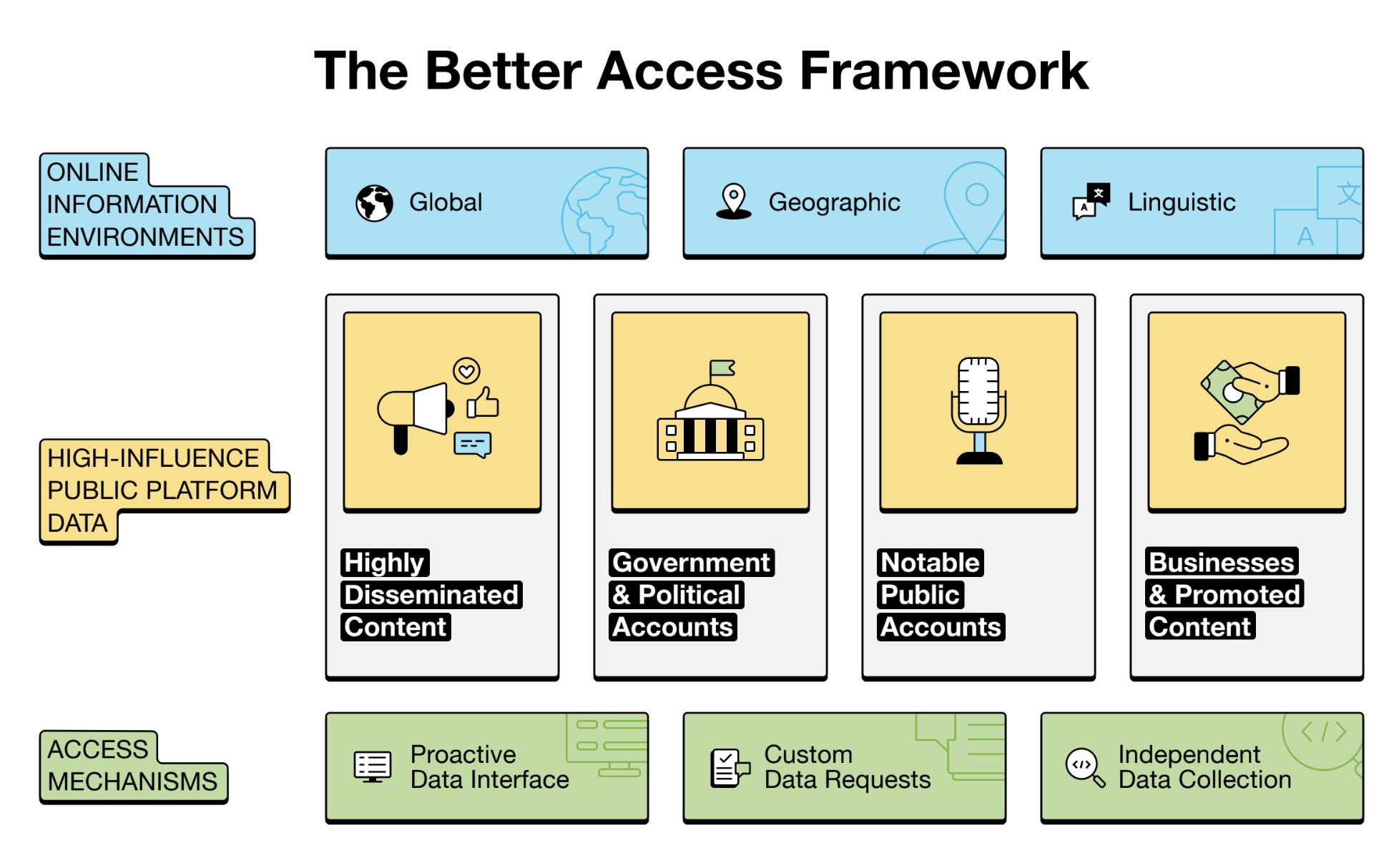
The bottom line? Regulations mandating data access, like the Digital Services Act, do help, but platforms are still opposing too resistance: the way for a fair data access is still long!
But we may have already gone a bit too far.
To give you a sense of why data access, why it matters, and what we could all do with it, I’m so happy to share the conversation I’ve had with Brandi Geurkink, currently the Executive Director of the Coalition for Independent Technology Research, who is on a mission to empower researchers to better study the online world!
Good read :)
The Interview
For clarity and readability, the transcript has been reviewed and lightly edited.
Why data access?
For technology to be shaped by and informed by the people who use it, we need to be able to ask questions that reflect their experiences—and surface negative experiences.
Data access is how we see into what people actually see. Tech companies are driven by making money, which leaves a ton out of the equation. Independent researchers and journalists - rooted in communities that are ignored and underserved - provide a critical counterweight to the industry.
Data access levels the playing field and opens a window where companies have intentionally created a black box.

And what do we get?
Better questions and better ideas. Under the Digital Services Act, for example, companies have to develop mitigations for harm; to know if those mitigations are actually working, you need the data to evaluate them.
What data should be accessed, and what would you look into?
A solid baseline of public social media data, aligned with the new framework that sets a gold standard for public data access for researchers and journalists.
We should know that tiny sliver of “highly disseminated public content” with disproportionate reach - what are the most viral things people are seeing, whose viewpoints they’re coming from, and whether there are paid motivations behind them. That’s essential if we want a more informed media ecosystem.
If we had unlimited platform data access, which behaviors, patterns, or features are critical to investigate right now?
Whether user controls actually work against recommendation systems. In my YouTube research with Mozilla, we built a browser extension and saw people getting recommendations that violated guidelines or simply weren’t wanted. YouTube said, “we have user controls.” We tested them. Largely, they didn’t work.
A concrete example: “Don’t recommend this channel” might block the main channel, but users still got flooded with near-duplicate clip channels - so they kept seeing what they’d said they didn’t want. That’s technology not working for people.
You talked of the “Data Desert”: over 60% of independent researchers face significant barriers. What are the obstacles?
Platforms have deliberately killed or walled off useful tools - CrowdTangle going away, X pricing its API at $42,000 a month, Reddit making API access extremely difficult.
We’ve also seen legal intimidation: cease-and-desists, lawsuits, suspensions of researcher accounts. And even where regulation exists, like the DSA, platforms still deny requests or create excessive gates.
You’ve said data access helps break monopoly power and conflicts of interest- and that platform data isn’t purely proprietary. Why should citizens care?
Because this is about how power operates. Look at the Romanian election: research into TikTok helped explain a candidate who seemed to come out of nowhere, and whether that activity aligned with electoral rules.
Digital spaces aren’t just online battlegrounds - they shape real-world outcomes. If we’re blindfolded, the power sits with states and platforms.
Researchers act as middleware - like the long fight for government transparency - so that citizens get a window into the mechanisms affecting their lives.
Are regulations like the Digital Services Act (that mandates data access for researchers) enough? What would you improve?
They help, but we need clear guidelines or best practices for what good compliance it looks like. Right now, platforms interpret “without undue delay” however they want and retain as much control as possible - asking for things like your birthday or requiring a Facebook account. That doesn’t match the spirit of the law.
The DSA is why these programs exist at all, which is good, but the point is enabling researchers to identify systemic risks and check whether platforms are actually mitigating them.
What’s your dream research project if you had unlimited data access?
Research into monopoly power - especially Google’s. The discovery in current cases has shown how much we didn’t know. With proper access, independent research - particularly from economists - could push this forward in a big way.
Save for Later
Meta makes money out of a lot of bad content, X is pushing some extremist theories, and TikTok doesn’t want you to stop scrolling. Not bad :) Ah, and why a safer online internet is no censorship whatsoever.
The guy who invented the Web is not feeling great, indeed.
At least some people are looking into what happens on these platforms, especially with advertising. Who Targets Me? Ah, and WhatsApp will be interoperable
A super interesting work on how to evaluate whether AI models are politically biased by Anthropic.
How delivery has changed restaurants forever. And a guy who coded an app while running a marathon.
A new podcast from the Atlantic!

The Bookshelf

More on not just how we get the data but why we need them, in “Access Rules”. It critically scrutinises what went wrong but, also, why we’re still on time to get things right when it comes to getting data.
📚 All the books I’ve read and recommended in Artifacts are here.
Nerding

I mentioned it above - if you’re into AI training or just want to share your own datasets to help open research and developments, the Mozilla Data Collective is the place to. Free, open, share it!
☕?
If you want to know more about Artifacts, where it all started, or just want to connect...