

Molto rumore per nulla
Molto rumore per nulla
Una pausa utile a capire le regole sui nostri dati e l'addestramento delle Intelligenze Artificiali

Qualche giorno fa, in molti condividevano questa storia Instagram
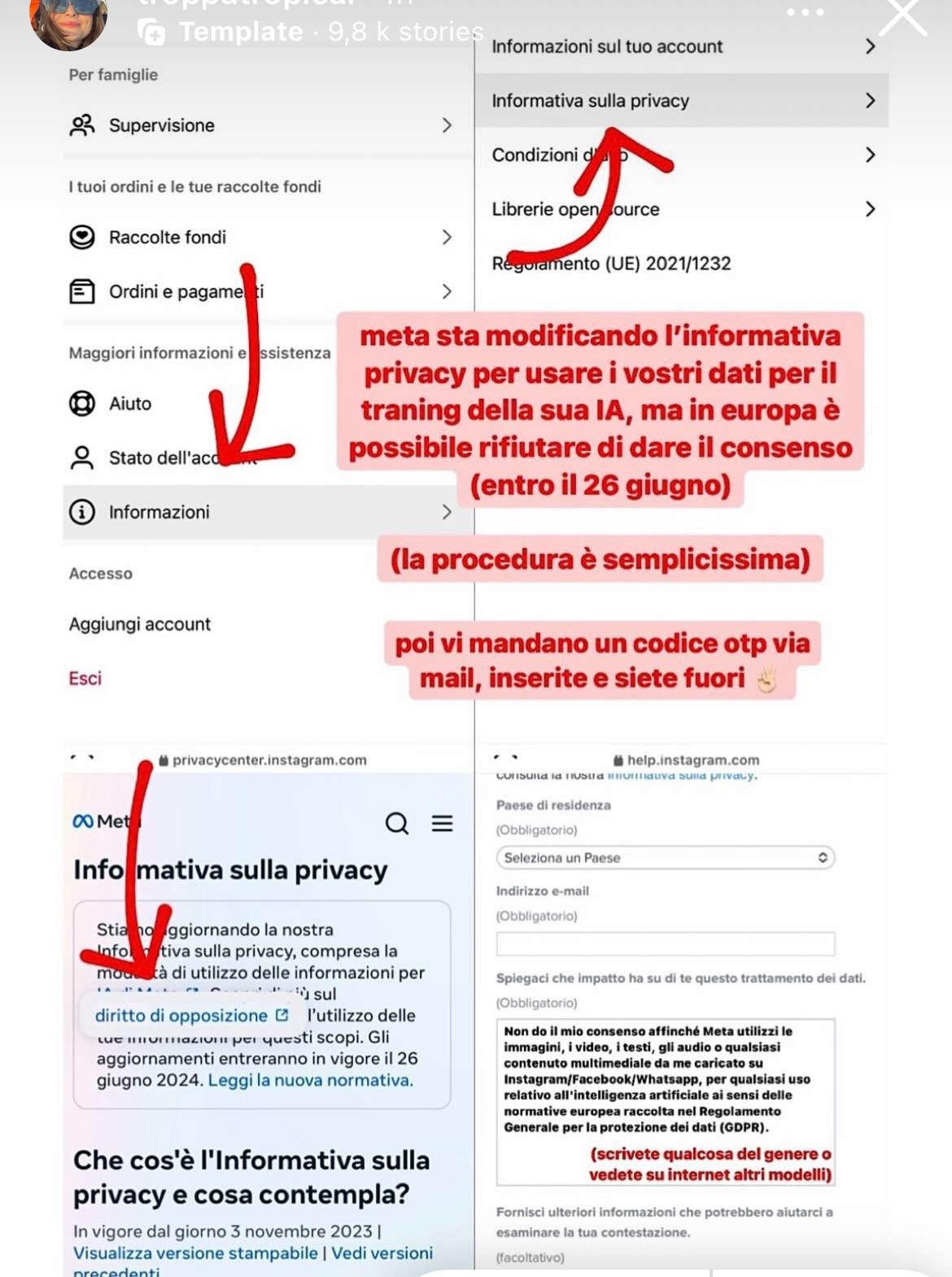
E no, non era una delle catene su Whatsapp che diventa a pagamento del 2012.
Anzi, era una utile guida per capire come impedire a Meta di utilizzare i nostri dati personali per addestrare le sue Intelligenze Artificiali. Dati che erano post, immagini, commenti, e storie degli utenti in UE e Regno Unito sia da Facebook che Instagram. Conversazioni private escluse, invece.
Questi dati sarebbero serviti a “riflettere le diverse lingue e riferimenti culturali, sociali e storici dei vari paesi europei” nelle IA di Meta, che sarebbero dovute arrivare tra pochi giorni. Una di queste era un assistente personale per ogni utente.

Uso passato e condizionale perché, alla fine, Meta ha cambiato idea. Per il momento, mette in pausa l’utilizzo di questi dati e, di conseguenza, non arriveranno queste AI in UE e Regno Unito.
Meta si è detta “delusa” e che si tratta di “un passo indietro per l’innovazione europea, la competizione nello sviluppo dell’AI e i benefici dell’AI per gli europei”.
Framing, here we go, again.
Quindi, sì, probabilmente aver condiviso quella storia e anche essersi districati nel non immediato modulo per negare il consenso all’utilizzo dei dati è stato, per ora, sostanzialmente inutile. Molto rumore per nulla, appunto.
Invece, più prezioso è stato il lavoro di NOYB, che il 6 giugno aveva inviato reclami a 11 autorità nazionali europee per la protezione dei dati. E sicuramente poi decisivi sono stati la Irish Data Protection Commission, l’autorità che in UE si occupa di Meta (e delle altre BigTech) in merito all’utilizzo dei nostri dati secondo il GDPR, e l’Information Commissioner’s Office, che ha compiti simili in Regno Unito.
Autorità che, infatti, sono menzionate da Meta nell’annuncio del cambio di posizione. In un comunicato uscito, tra l’altro, di venerdì pomeriggio, che non è sicuramente il momento migliore per dare rilevanza ad una notizia.
In questo caso, poco rumore per qualcosa di forse importante.

Comunque, anche se al momento questa vicenda è ferma, è uno spunto utile per capire diverse cose sull’AI e i nostri dati personali che, se è sbagliato concepire come il nuovo petrolio che alimenta l’IA, sono comunque tra i pilastri della rivoluzione che stiamo vivendo.
E allora questa Artifacts prima vede cosa ci “chiedeva” Meta e perché, poi cosa cambia ora che c’è l’AI per i nostri dati e infine perché in realtà potrebbe non cambiare niente o, comunque, questa potrebbe non essere una rivoluzione poi così nuova.
La Storia
Innanzitutto, utilizzare dati personali in UE è illegale, di default. Perché sia permesso, infatti, serve una motivazione valida.
Nel concreto, qualsiasi azienda o terza parte raccolga e utilizzi dei dati personali, deve fare riferimento ad una delle giustificazioni elencate dall’art.6 del GDPR: consenso, legittimo interesse, necessità contrattuale, obbligo legale, vitale interesse, pubblico interesse.
Nel caso dell’addestramento delle IA, la questione è decisamente intricata, se non altro perché l’IA stessa non è MAI menzionata nel GDPR. Bisogna quindi riflettere sul GDPR e adattarlo.
Per l’accademia e lo European Data Protection Board (EDPB), le due basi considerabili per l’IA sono o il consenso o il legittimo interesse.
Il consenso prevederebbe che quelli che “producono” i dati, ossia i data subjects (noi), siano d’accordo che il data controller, Meta nel caso di sopra, li utilizzi per un certo scopo. Consenso che deve essere “dato liberamente, specifico e non ambiguo”, come spiegavo qui.
Nel caso dell’IA, però, il consenso a queste condizioni è molto difficile da ottenere perché gli utenti non necessariamente capiscono a pieno l’utilizzo dei dati, è molto difficile garantire totale trasparenza, e poi c’è una granularità molto alta dei dati stessi e quindi dei cittadini a cui chiedere.
Se il consenso, quindi, forse non è la base legale adatta al training dell’IA, lo è invece il legittimo interesse. Che, infatti, secondo l’EDPB “is probably the right one”.
3 condizioni da considerare sul legittimo interesse:
che sia, appunto, legittimo, e quindi il data controller persegua scopi ragionevoli - fare il training;
che ci sia una necessità per la quale è giustificabile l’utilizzo dei dati - no dati, no training;
che sia bilanciato con i diritti e le libertà dei data subjects, considerando contesto, che dati sono utilizzati e l’impatto.
Condizioni, queste, più facili da rispettare rispetto a quelle del consenso per come funzionano i training delle IA. Anche perché, banalmente, il legittimo interesse può essere “presunto”, quindi non c’è bisogno di ottenere il “sì” dei data subjects.
Insomma, chi usa dati personali per il training delle IA sembra poter farlo perché ha un legittimo interesse.
Una prova ulteriore è che quando un anno fa il Garante Privacy fermava ChatGPT in Italia, riconosceva proprio il legittimo interesse come base plausibile per il trattamento dei dati.
E, se tutto questo rumore è stato per Meta, in realtà anche OpenAI, Twitter, Google, Snapchat dicono - dopo diversi scroll di mouse - di fare affidamento proprio sul legittimo interesse nelle loro Privacy policy. Anzi, almeno Meta è stata un po’ più chiara ed esplicita.
Oltre alla base legale, però, questa vicenda è resa ancora più complicata da un altro fattore: in origine questi dati NON sono stati raccolti per il training delle IA.
Anzi, i dati in mano a Meta, Google, Twitter etc. sono stati raccolti nel corso degli anni per altri scopi, come ad esempio le pubblicità targetizzate. Però, con l’IA che ora è la priorità e i dati per addestrarla che sono preziosissimi, chiaramente chi ha dati a disposizione vuole usarli ANCHE per l’IA.
In gergo, si tratta di repurposing, ossia dare una nuova finalità a qualcosa che prima ne aveva una diversa.
Ed è un concetto chiave per il futuro del training dell’IA, che si affida prevalentemente su dati raccolti per scopi altri. Proviamo a capire come funziona.
Il GDPR stabilisce una purpose limitation, ossia che i dati sono raccolti per specifici ed espliciti scopi e non possono essere processati per scopi incompatibili con quelli originali.
Quindi? Va fatto un test di compatibilità per capire se il nuovo scopo - il training delle IA in questo caso - può reggere e se esista una base legale appropriata.
Per gli amanti dei bullet point, possiamo riassumere la liceità del repurposing in 2 condizioni:
la nuova elaborazione dei dati è compatibile con quella originaria;
esiste una base legale su cui fare affidamento, quella che secondo Meta e molti altri è il legittimo interesse.
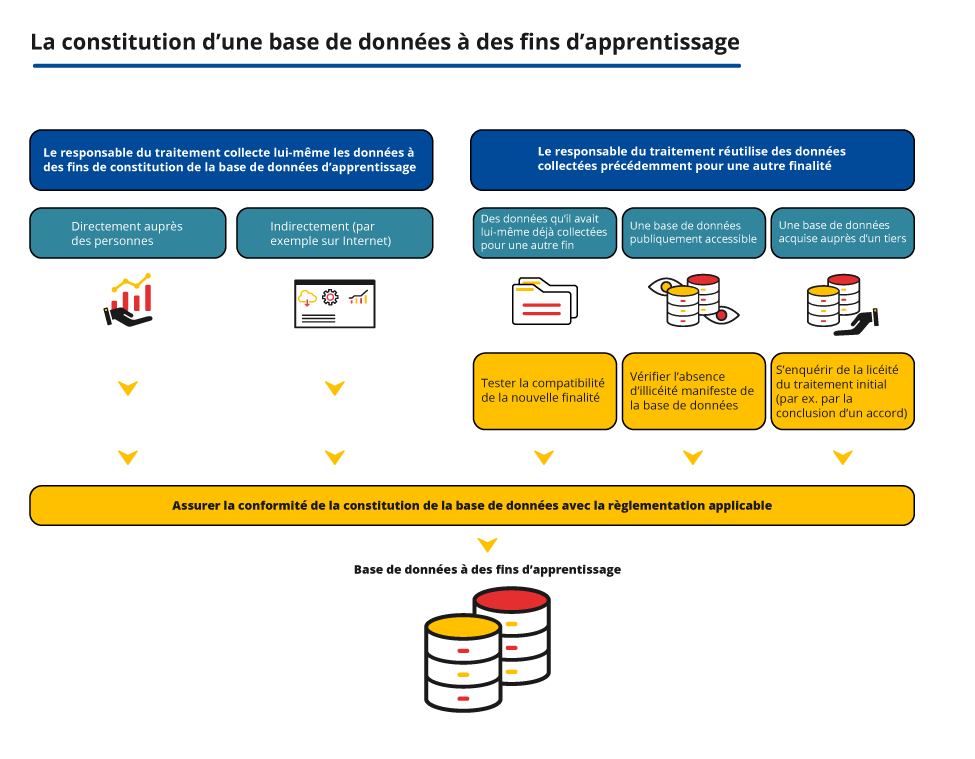
Questo, comunque semplificato, è quello che deve fare Meta o chi altro usa dei dati raccolti in passato per addestrare IA nel presente.
Qualora il repurposing sia possibile, tuttavia, rimane il right to object per i cittadini, che possono ovviamente opporsi all’uso dei loro dati personali. Ed è esattamente quello che Meta voleva permettere e il senso di quella storia Instagram da cui abbiamo iniziato.
E, seppur ora magari questa vicenda specifica sia in pausa, tenere a mente queste regole è molto utile per i mesi che verranno.
Specialmente per le BigTech, per le quali i dati sono stati l’ingrediente essenziale del successo in passato, e rappresentano ora anche un vantaggio competitivo enorme per la corsa all’IA.
Una corsa nella quale non si riparte certo da zero, ma anzi chi ha dati, infrastrutture per processarli, risorse economiche, ed expertise, è già decisamente più avanti degli altri.
Tutte dinamiche per le quali, infatti, anche sull’IA a fare la voce grossa sono i soliti noti e, probabilmente, è anche difficile immaginare che vada diversamente.
Un vantaggio, sia chiaro, guadagnato e meritato nel tempo. Ma che, allo stesso tempo, non può tradursi nell’aggirare le regole sui dati personali.
Regole che abbiamo chiarito, ma ora bisogna vedere come va davvero la partita. Della quale, poi, forse abbiamo già avuto un assaggio.
Save for Later
Perché il futuro digitale dell’Europa è meglio di quello che pensiamo.
C’è chi ha hackerato le elezioni europee, in positivo. Sembra sia andata bene sulla disinformazione, ma non benissimo.
Come invece l’estrema destra avrebbe utilizzato l’IA durante le europee.
Apple presenta la sua Apple Intelligence, che funziona perché è noiosa ma efficace. Un mio pensierino a riguardo:
Come Google sta mandando all’aria Internet, dicono.
Tantissime cose utili da leggere su come funzionano gli algoritmi dei social.
Immanence, la startup di
sull’impatto sociale dell’Intelligenza Artificiale, cerca un Operations Manager.
Sono stato al We Make Future a parlare di Artifacts, e di come la penso, la scrivo e la mando. Bella roba, insieme ad altri newsletterati.

Lo Scaffale

Semplicemente uno dei miei libri preferiti sulla tecnologia. “Internet fatta a pezzi” di Stefano Quintarelli e Vittorio Bertola è una di quelle letture che non si possono non fare se si è interessati a Internet e le sue dinamiche politiche e economiche. Lo consiglio oggi perché sennò poi lo rimando sempre.
📚 Tutti, ma proprio tutti, i libri consigliati in Artifacts sono raccolti qui
Nerding

Per chi vuole tenere traccia dei propri pensieri in maniera ordinata, Diarium è fatta apposta. Conserva tutto in maniera crittografata, quindi è anche sicura e non rischi data leak dei tuoi pensieri.